
Interactive 3D scenes are increasingly vital for embodied intelligence, yet existing datasets remain limited due to the labor-intensive process of annotating part segmentation, kinematic types, and motion trajectories. We present REACT3D, a scalable zero-shot framework that converts static 3D scenes into simulation-ready interactive replicas with consistent geometry, enabling direct use in diverse downstream tasks. Our contributions include: (i) openable-object detection and segmentation to extract candidate movable parts from static scenes, (ii) articulation estimation that infers joint types and motion parameters, (iii) hidden-geometry completion followed by interactive object assembly, and (iv) interactive scene integration in widely supported formats to ensure compatibility with standard simulation platforms. We achieve state-of-the-art performance on detection/segmentation and articulation metrics across diverse indoor scenes, demonstrating the effectiveness of our framework and providing a practical foundation for scalable interactive scene generation, thereby lowering the barrier to large-scale research on articulated scene understanding.
Embodied AI requires large-scale, physically interactive 3D environments, but building them today hinges on slow, expert-heavy annotations of parts, joints, and motions. Meanwhile, vast static 3D datasets already exist yet remain inert for interaction and simulation. Our motivation is to unlock the latent interactivity of these static assets—recovering articulations and consistent geometry automatically—so that researchers can train and evaluate agents at scale without new data collection or manual labeling. By converting abundant static scenes into reliable interactive environments, we aim to collapse the data bottleneck that currently limits progress in articulated scene understanding and embodied intelligence.
We propose a novel, application-driven framework for converting high-quality static scenes into physics-aware, interactive environments:
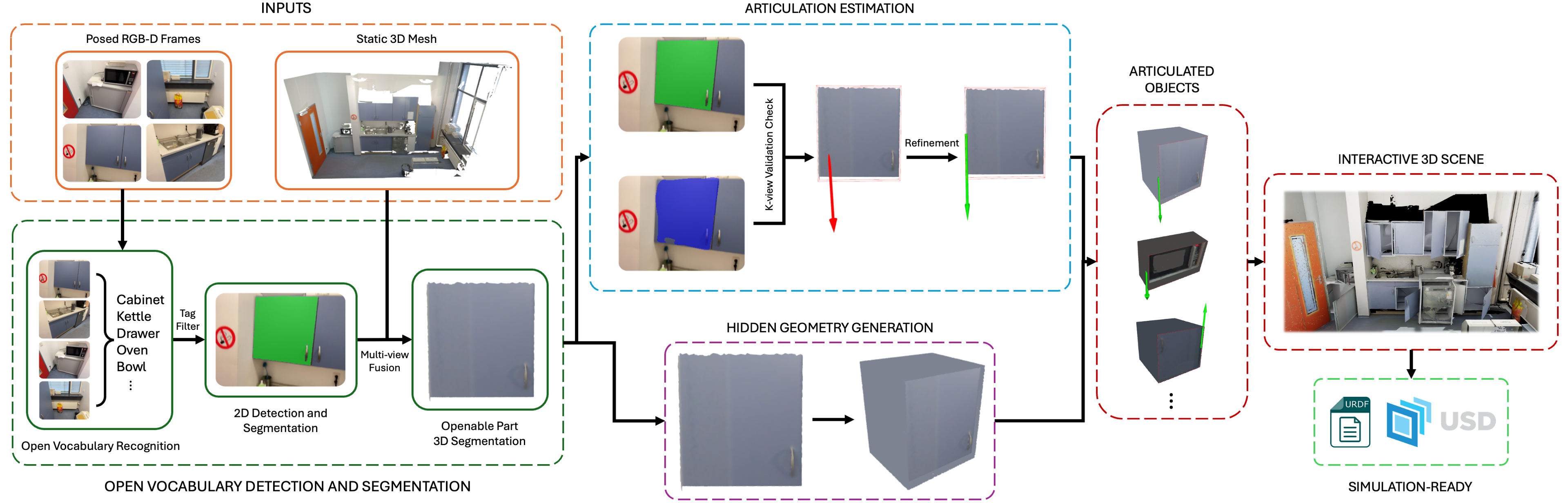
Given a static 3D scene, our method first applies open-vocabulary detection to identify openable objects and segmentation to extract their movable parts. We then estimate articulations and generate hidden geometry to obtain interactive objects. Finally, they are integrated with the static background to produce a simulation-ready interactive scene.
Predicted 2D Mask

Segmented Mesh

Predicted Joint

Refined Joint

Interactive Object

Opened Object

From left to right, the figure shows key intermediate results of interactive object generation. In the last column, the thin red line highlights the contour of the base part.






We show three example input scenes from ScanNet++ (top row) and their corresponding interactive replicas generated by REACT3D (bottom row), visualized in Isaac Sim. Our method robustly converts diverse object types, shapes, sizes, and articulation mechanisms, producing high-quality interactive scenes.
We showcase the interactive scenes generated by REACT3D in two widely used simulators, Isaac Sim and ROS. The videos demonstrate the physical interactivity of various objects. Users can manipulate each single object through GUI, highlighting the versatility and applicability of our generated scenes in different simulation environments.
@misc{huang2025react3drecoveringarticulationsinteractive,
title={REACT3D: Recovering Articulations for Interactive Physical 3D Scenes},
author={Zhao Huang and Boyang Sun and Alexandros Delitzas and Jiaqi Chen and Marc Pollefeys},
year={2025},
eprint={2510.11340},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.11340},
}